Each time any one of the billion Facebook users visits the social networking site,the company's servers must assemble data--user posts,likes,shares,images--from hundreds or even thousands of different servers around the globe.The page must be created on the fly and within a few hundred milliseconds.
No simple task,but thus far,Facebook has only offered brief glimpses of how its servers execute this challenging operation.This week though,the company will offer an architectural overview of its data management and delivery infrastructure at the 2013 Usenix Annual Technical Conference,being held in San Jose,California.
Facebook engineer Mark Marchukov,who will be doing the presentation at Usenix on Wednesday,has also posted a blog entry with more details.
Because the structure--and volume--of the data that Facebook serves is so different from the sort typically handled by a commercial relational database,the company developed its own data store,called TAO("The Associations and Objects").Facebook describes TAO in the accompanying Usenix paper as"a geographically distributed,eventually consistent,graph store optimized for reads."
"Several years ago,Facebook relied entirely on an open-source stack--Apache,MySQL,Memcache,PHP.We were very good at customizing open-source software to our needs,"said Facebook engineering director Venkat Venkataramani in an interview."But then we started thinking what a data store would look like that was built by Facebook for Facebook."
While Facebook has not released as open source any of the TAO code yet,the architectural details the company has provided could influence the development of new types of data stores and other software,in much the same way that company-published white papers on Amazon Dynamo and Google BigTable paved the way for a new generation of NoSQL databases.
The work shows the validity of the graph data model that Facebook relies on to make associations between people and events,as well as the power of distributed data management.
"Almost all enterprises work on a relational data model,but as we move to the cloud,the scalability challenges that a lot of enterprises will face in the future will be quite different than what the scenery looks like today.We may be just a little ahead of the curve there,"Venkataramani said.
The TAO API(application programming interface)"makes the entire data store feel like one unified system,while on the back end,we are able to distribute it across a wide number of machines,data centers and even regions,"Venkataramani said.
TAO has been in full-scale deployment at Facebook for about two years.During peak hours,TAO can process more than 1.6 billion reads per second and 3 million writes per second.
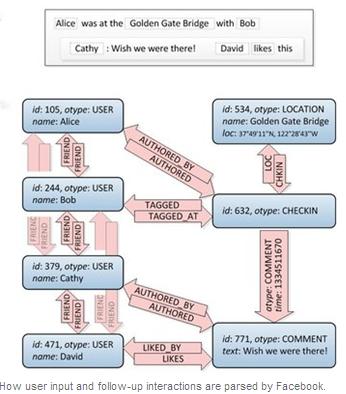
Initiated in 2007,TAO started as a project to build an API that would provide an easy way for Facebook and third-party developers to build new services based on user data.The API offered data on the graph data model,which categorized all information as either objects or associations.An object could be a user or a specific post,and an association could be a pre-defined relationship between two nodes,such as a user"liking"a post.Each node or association can originate from any Facebook server around the world.
The Objects and Associations API paved the way for a number of very successful Facebook features,such as likes and events.But it also placed a heavy burden on the servers and software in the way that it requested data.So in 2009,Facebook engineers started work on developing a distributed service based on objects and associations that would be better suited for serving information in graph data structures.
Originally,Facebook user data was stored on MySQL,queried through PHP,and cached for quick accessibility on Memcache.Over time,the immense amount of data Facebook captured required the company to divide the database into hundreds of thousands of logical shards,with each shard holding a unique portion of data.
MySQL,which Facebook now views as a component of TAO,provides only persistent,or long-term,storage of data.Most of the information that users see is assembled from TAO's globally distributed in-memory cache,which is automatically populated with data as it is requested and submitted by users,while bumping out the least recently used(LRU)data.Only requests for older,rarely consulted data reach back to the MySQL databases.
The company no longer uses Memcache for caching duties(though Facebook continues to use the software in other systems).
Technically speaking,Memcache is closer to an in-memory data store rather than a caching mechanism,Venkataramani explained.As a result,the software didn't handle typical caching duties such as automatically maintaining consistency with the source database,or automatically drawing data from a database that has been requested by users.As a result,Facebook engineers had to write code to enable these features piecemeal,which complicated the overall architecture.
Memcache also required a fair amount of expertise from the developers who built Facebook user-facing products,Venkataramani noted.If these developers did not understand all the nuances of the Memcache,their products could have data inconsistencies,bugs and performance issues.
The TAO caching layer is run on the servers by a collection of daemons,mostly written in C and C++.They route write requests,execute read requests and maintain consistency with other caching servers.TAO cache servers are one of two types:leaders or followers.Each leader cache is assigned to a single database shard,and is responsible for maintaining the consistency of the data between itself and the shard.
The leader cache periodically sends updates to the follower caches,which are the caches that users first hit when requesting data from Facebook.Facebook works on the principle of eventual consistency,in which data written to Facebook will be made available for access,though a few seconds may lapse before the data is written to all the database and the caches.Eventual consistency has long been a behavior associated with using a distributed database.
TAO offers a number of advantages for Facebook,Venkataramani said.First,it scales easily for traffic spikes,simply by adding more follower servers.It also is easy to upgrade with because it cleanly separates the caching layer from the persistent data storage layer,allowing the company to update and scale either one without affecting the other.The API also cleanly separates the product logic from the data access.As a result,"when building products,the product engineers just use the API to store and access data,"Venkataramani said.



